Add a Backend to MQBench: Quick Start
MQBench is able to do quantization over many different backends and quantization algorithms, which relys on the independence of hardware(backends) and software(algorithms). To support a new backend, h/w and s/w should be added.
We provide a typical work-flow:
Add
FakeQuantizeAffineto simulate the hardware behavior. Add correspondingObserverto provideFakeQuantizeAffinewith needed infomation.Add
ModelQuantizerto insert quantize nodes into the model.Add ONNX-Backend translator to deploy the output graph.
In the following sections, we will show how to add a backend gived a specific hardware platform.
FakeQuantize, Observer and Quantization Scheme
Quantization Function
Now we have a fake quantize affine ExampleQuant, where \(x, s, z, n, p\) are the tensor, scale, zero point, lower bound and upper bound:
Then we have to deploy the corresponding forward/backward in mqbench/fake_quantize/, like:
1class ExampleQuant(torch.autograd.Function):
2 @staticmethod
3 def forward(ctx, x, s, z, n, p):
4 q = f_1(x, s, z, n, p)
5 ctx.save_for_backward(x, q, s, z, n, p)
6 return qx
7
8 @staticmethod
9 def backward(ctx, grad_outputs):
10 x, q, s, z, n, p = ctx.saved_tensors
11 grad_x, grad_s, grad_z, grad_n, grad_p = f_2_to_6(x, q, s, z, n, p)
12 return grad_x, grad_s, grad_z, grad_n, grad_p
13
14 @staticmethod
15 def symbolic(g, x, scale, zero_point, quant_min, quant_max):
16 return g.op("::ExampleQuant", x, scale, zero_point, quant_min_i=quant_min, quant_max_i=quant_max)
Then, wrap it via QuantizationBase.
1class ExampleFakeQuantize(QuantizeBase):
2 def __init__(self, observer, scale=1., zero_point=0., use_grad_scaling=True, **observer_kwargs):
3 super(TqtFakeQuantize, self).__init__(observer, **observer_kwargs)
4 self.scale = Parameter(torch.tensor([scale]))
5 self.zero_point = Parameter(torch.tensor([zero_point]))
6
7 def forward(self, X):
8 # Learnable fake quantize have to zero_point.float() to make it learnable.
9 if self.observer_enabled[0] == 1:
10 self.activation_post_process(X.detach())
11 _scale, _zero_point = self.activation_post_process.calculate_qparams()
12 self.scale.data.copy_(_scale)
13 self.zero_point.data.copy_(_zero_point.float())
14 if self.fake_quant_enabled[0] == 1:
15 X = ExampleQuant.apply(X, self.scale, self.zero_point, self.quant_min, self.quant_max)
16 return X
Observer
The quantizable statistics are collected by Observer. It is enabled at calibration stage, and do its job. Given g(x) is needed to calculate quantization params, we can deploy like:
1class ExampleObserver(ObserverBase):
2 def __init__(self, dtype=torch.quint8, qscheme=torch.per_tensor_affine,
3 reduce_range=False, quant_min=None, quant_max=None, ch_axis=-1, pot_scale=False,
4 factory_kwargs=None):
5 super(ExampleObserver, self).__init__(dtype, qscheme, reduce_range, quant_min, quant_max,
6 ch_axis, pot_scale, factory_kwargs)
7
8 def forward(self, x_orig):
9 r"""Records the running minimum and maximum of ``x``."""
10 x = x_orig.to(self.min_val.dtype)
11 self.collected = g(x)
12 return x
13
14 def calculate_qparams(self):
15 s, z, n, q = self.collected
16 return s, z, n, q
Register your FakeQuantize/Observer for your backend
Now we have our FakeQuantize and Observer ready, then register it for your platform at mqbench.prepare_by_platform. Import them in just like the FakeQuantizes and Observers already here. Define your backend at the enumeration of BackendType. Then register the quantization scheme, which includes the FakeQuantize and Observer you have just defined and other details like Per-Channel/Tensor, Sym/Asym Quantization and so on.
Add Quantization Node into models
We have the quantization affine and observer and the next step is to insert them as nodes into GraphModule. We have provided lots of APIs for quantizing normal OPs like conv/fc/deconv and so on. If the backend supports what we provided in mqbench.custom_quantizer, just to re-use the logic used in it.
If there are some constrains for the backend, a normal flow is to extend the TensorRT backend which quantizes the input of centain ops.
Quantize a new module(ExampleMod)/function(example_func)
1@property
2def module_type_to_quant_input(self) -> tuple:
3 return (
4 ...
5 # Example Module
6 ExampleMod
7 ) + self.additional_module_typ
8
9
10@property
11def function_type_to_quant_input(self) -> list:
12 return [
13 ...
14 example_func
15 ] + self.additional_function_type
Deploy Models for the backend
The deploy stage will fuse bn into previous modules and remove FakeQuantize nodes from the GraphModule. Just register mqbench/convert_deploy.convert_merge_bn for your backend.
We introduced ONNX as a intermediate representation to hold the network infomation, and the quantization related infomation will be dumped into a single json file. First we dump the model with quantization nodes which accquires registeration of mqbench/convert_deploy.convert_onnx. The ONNX graph with quantization nodes is shown as following.
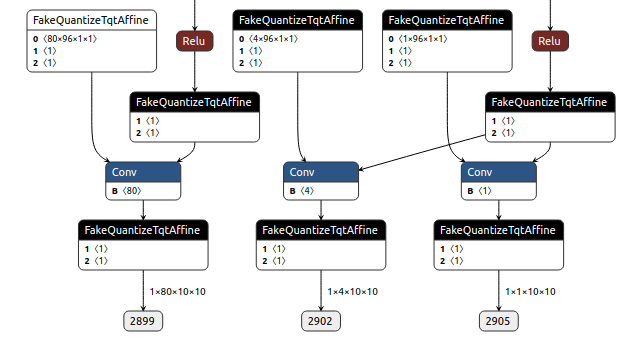
ONNX Graph with FakeQuantize
Second, remove the fake quantize node and collect needed infomation. For linear/logarithmic quantization, we have mqbench.deploy.remove_fakequantize_and_collect_params and mqbench.deploy.remove_fakequantize_and_collect_params, which usually needs just simple(or no) changes for other platform. Let’s assume your platform needs (scale, zero_point, quant_min, quant_max, round_mode) to run a model. At mqbench.deploy.deploy_linear’s clip ranges, add your logic to compute all the things from the ONNX graph(with quantization node). The ONNX graph without FakeQuantize is show as following.
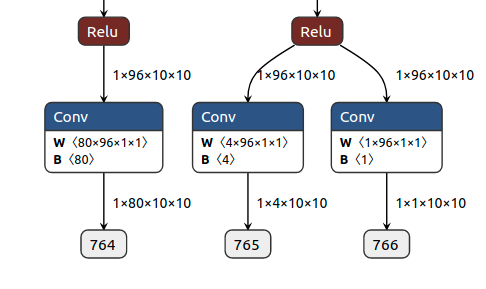
ONNX Graph after Removing FakeQuantizeAffine
With all these steps done, platform-specific translation should be integrated. If your platform’s runtime does not support ONNX model input, translate it into preferred form.
1class LinearQuantizer_process(object):
2 ...
3 def remove_fakequantize_and_collect_params(self, onnx_path, model_name, backend):
4 ...
5 if backend == 'example':
6 # model is the onnx, context
7 # context is the quantization info'd dict
8 example_model = do_translate(model, context)
9 logger.info("Finish example model converting process.")
We take Vitis-AI as a example platform here.
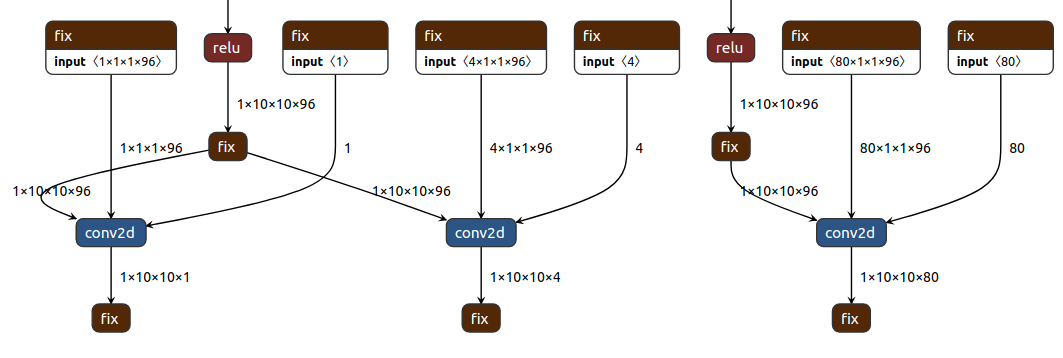
Platform Based Model Representation